【WebAssembly】プリミティブ表示までやってみた【WebGPU】
はじめに
暇を見て WebGPU を勉強してます。
検証中は main() 内で完結させる感じで作ってます。
確認はこちら
動作確認出来た環境は以下のみです。
- Windows Chrome
- Windows Edge
- macOS Chrome
シェーダーの準備
シェーダーは WGSL で書きます。書式は Rust とのことです。
HLSL GLSL PSSL などと比べるとかなり書きやすいものになっています。
今回は単純なシェーダーをコードに直接書いて、使うことにします。
頂点座標と頂点色、回転角度を受け取り回転させて表示するだけの単純なものです。
シェーダー
HLSL や GLSL がわかればすぐ理解できると思います。
char const wgsl_shader[] = R"(
struct VSIn {
@location(0) pos: vec2<f32>,
@location(1) color: vec3<f32>,
};
struct V2F {
@builtin(position) pos: vec4<f32>,
@location( 0) color: vec3<f32>,
};
struct Uniform
{
angle: f32,
};
@group(0) @binding(0) var<uniform> _Uniform : Uniform;
@vertex
fn vert( in: VSIn) -> V2F {
var out: V2F;
let cs = cos( _Uniform.angle);
let sn = sin( _Uniform.angle);
let mtx: mat2x2<f32> = mat2x2<f32>( cs, -sn, sn, cs);
let pos = in.pos * mtx;
out.pos = vec4<f32>( pos.x, pos.y, 0.0f, 1.0f);
out.color = in.color;
return out;
}
@fragment
fn frag( in: V2F) -> @location(0) vec4<f32> {
return vec4<f32>( in.color, 1.0f);
}
)";バーテックスシェーダーで 頂点座標と頂点色を受け取り、座標計算しフラグメントシェーダーに流します。
フラグメントシェーダーはただ受け取った色を出力しています。
角度パラメータ用に変数を渡すには
var<uniform>を使って受け渡しします。
struct Uniform
{
angle: f32,
};
@group(0) @binding(0) var<uniform> _Uniform : Uniform;今回は回転のみ受け取り _Uniform に代入しています。
バーテックスシェーダーは頂点単位で呼ばれ、 VSIn を受け取り
_Uniform.angle を使って座標を回転させ
V2F へ代入し 出力しています。
頂点色はそのまま V2F へ代入しています。
@vertex
fn vert( in: VSIn) -> V2F {
var out: V2F;
let cs = cos( _Uniform.angle);
let sn = sin( _Uniform.angle);
let mtx: mat2x2<f32> = mat2x2<f32>( cs, -sn, sn, cs);
let pos = in.pos * mtx;
out.pos = vec4<f32>( pos.x, pos.y, 0.0f, 1.0f);
out.color = in.color;
return out;
}フラグメントシェーダーは ピクセル単位で呼ばれ、 V2F を受け取り色を計算します。
今回はそのまま受け取った色を出力します。
@fragment
fn frag( in: V2F) -> @location(0) vec4<f32> {
return vec4<f32>( in.color, 1.0f);
}シェーダーのビルド
wgpu::Device::CreateShaderModule() でシェーダーをコンパイルします。
wgpu::ShaderModuleWGSLDescriptor shaderModuleWGSLDescriptor{};
shaderModuleWGSLDescriptor.code = wgsl_shader;
wgpu::ShaderModuleDescriptor shaderModuleDescriptor
{
.nextInChain = &shaderModuleWGSLDescriptor,
};
wgpu::ShaderModule gpuShaderModule = gpuDevice.CreateShaderModule( &shaderModuleDescriptor);頂点情報の作成
頂点バッファを用意します。ひとまず正三角形を作り、各頂点にRGBを設定しています。
その後 queue へ書き込んでいます。
const float pi = 2*std::asin(1);
// 頂点情報
float const vertices[] =
{
std::sinf( 2*pi*0/3.0f), std::cosf( 2*pi*0/3.0f), 0.0f, 0.0f, 1.0f,
std::sinf( 2*pi*1/3.0f), std::cosf( 2*pi*1/3.0f), 1.0f, 0.0f, 0.0f,
std::sinf( 2*pi*2/3.0f), std::cosf( 2*pi*2/3.0f), 0.0f, 1.0f, 0.0f,
};
wgpu::BufferDescriptor vertexBufferDescriptor
{
.label = "vertices",
.usage = wgpu::BufferUsage::CopyDst | wgpu::BufferUsage::Vertex,
.size = sizeof( vertices),
};
wgpu::Buffer vertexBuffer = gpuDevice.CreateBuffer( &vertexBufferDescriptor);
queue.WriteBuffer( vertexBuffer, 0, vertices, sizeof( vertices));頂点レイアウトを設定します。
頂点レイアウトの設定
頂点バッファとシェーダーの VSIn と合わせてレイアウトデータを設定します。
// 頂点情報レイアウト設定
wgpu::VertexAttribute vertexAttributeArray[] =
{
{
.format = wgpu::VertexFormat::Float32x2,
.offset = 0,
.shaderLocation = 0,
},
{
.format = wgpu::VertexFormat::Float32x3,
.offset = 2 * sizeof( float),
.shaderLocation = 1,
},
};vertexAttributeArray[0] は 頂点座標 X Y の float*2 になります。
vertexAttributeArray[1] は頂点色で RGB の float*3 です。
VertexAttribute.offset は頂点バッファの一頂点情報のオフセット値を設定します。
VertexAttribute.shaderLocation はシェーダーの @location() の値です。
0が @location(0) pos
1が @location(1) color
に該当します。
VertexBufferLayout を作っておきます。
wgpu::VertexBufferLayout vertexBufferLayout
{
.arrayStride = 5 * sizeof(float),
.attributeCount = std::size( vertexAttributeArray),
.attributes = vertexAttributeArray,
};VertexBufferLayout.arrayStride は一頂点バッファサイズ
VertexBufferLayout.attributeCount は構造体内のメソッドの数
VertexBufferLayout.attributes はレイアウト情報のポインタ
インデックス情報の作成
頂点インデックスバッファを作成します。
メモリアライメントの関係で4バイトに揃えるため、indicesに無用の 0 を追加しています。
バッファを作成出来たら queue.WriteBuffer で書き込みます。
// インデックス情報
uint16_t const indices[] = { 0, 1, 2, 0, };
wgpu::BufferDescriptor indexBufferDescriptor
{
.label = "indices",
.usage = wgpu::BufferUsage::CopyDst | wgpu::BufferUsage::Index,
.size = sizeof( indices),
};
wgpu::Buffer indexBuffer = gpuDevice.CreateBuffer( &indexBufferDescriptor);
queue.WriteBuffer( indexBuffer, 0, indices, sizeof( indices));フラグメント情報の設定
ブレンド設定
カラーのブレンド設定します。
wgpu::BlendState blendState
{
.color = wgpu::BlendComponent
{
.operation = wgpu::BlendOperation::Add,
.srcFactor = wgpu::BlendFactor::SrcAlpha,
.dstFactor = wgpu::BlendFactor::OneMinusSrcAlpha,
},
.alpha = wgpu::BlendComponent
{
.operation = wgpu::BlendOperation::Add,
.srcFactor = wgpu::BlendFactor::Zero,
.dstFactor = wgpu::BlendFactor::One,
},
};
wgpu::ColorTargetState colorTargetState
{
.format = gpuTextureFormat,
.blend = &blendState,
.writeMask = wgpu::ColorWriteMask::All,
};.format = gpuTextureFormat,はカラーフォーマットの設定で
wgpu::TextureFormat gpuTextureFormat = gpuSurface.GetPreferredFormat( gpuAdapter);でサーフェスのカラーフォーマットを設定しています。
フラグメント設定
フラグメントシェーダーとブレンド設定の関連付けをします。
wgpu::FragmentState fragmentState
{
.module = gpuShaderModule,
.entryPoint = "frag",
.constantCount = 0,
.constants = nullptr,
.targetCount = 1,
.targets = &colorTargetState,
};Uniformバッファーの設定
uniformレイアウト設定
シェーダーの uniform のレイアウトを設定します。
float angle; は4バイトですが、16バイト以上の設定でないと動きませんでした。
uniform のメモリアライメントは 16バイト単位で設定する必要があるようです。
wgpu::BindGroupLayoutEntry bindGroupLayoutEntryArray[]
{
{
.binding = 0,
.visibility = wgpu::ShaderStage::Vertex | wgpu::ShaderStage::Fragment,
.buffer = wgpu::BufferBindingLayout
{
.type = wgpu::BufferBindingType::Uniform,
.hasDynamicOffset = false,
.minBindingSize = 0,
},
},
};
wgpu::BindGroupLayoutDescriptor bindGroupLayoutDescriptor
{
.entryCount = std::size( bindGroupLayoutEntryArray),
.entries = bindGroupLayoutEntryArray,
};
wgpu::BindGroupLayout gpuBindGroupLayout = gpuDevice.CreateBindGroupLayout( &bindGroupLayoutDescriptor);binding は シェーダーの @binding(0) と揃えます。今回は 0 のみしか使っていません。
@binding(0) var<uniform>uniformバッファーを作成
回転情報用に uniformバッファーを作成します。
こちらも binding をシェーダーに揃えます。
wgpu::BufferDescriptor uniformBufferDescriptor
{
.label = "uniform",
.usage = wgpu::BufferUsage::CopyDst | wgpu::BufferUsage::Uniform,
.size = 4*sizeof( float),
};
wgpu::Buffer uniformBuffer = gpuDevice.CreateBuffer( &uniformBufferDescriptor);BindGroupEntry 設定
uniformバッファーのレイアウトの設定をします。
wgpu::BindGroupEntry bindGroupEntryArray[]
{
{
.binding = 0,
.buffer = uniformBuffer,
.offset = 0,
.size = 4*sizeof(float),
.sampler = nullptr,
.textureView = nullptr,
},
};
wgpu::BindGroupDescriptor bindGroupDescriptor
{
.layout = gpuBindGroupLayout,
.entryCount = std::size( bindGroupEntryArray),
.entries = bindGroupEntryArray,
};
wgpu::BindGroup gpuBindGroup = gpuDevice.CreateBindGroup( &bindGroupDescriptor);レンダリングパイプライン作成
これまで作成したバッファやレイアウト設定を元にレンダリングパイプラインを作成します。
今回は 辺の向きとカリングは無効に設定しています。
wgpu::PipelineLayoutDescriptor pipelineLayoutDescriptor
{
.bindGroupLayoutCount = 1,
.bindGroupLayouts = &gpuBindGroupLayout,
};
wgpu::PipelineLayout gpuPipelineLayout = gpuDevice.CreatePipelineLayout( &pipelineLayoutDescriptor);
wgpu::RenderPipelineDescriptor renderPipelineDescriptor
{
.layout = gpuPipelineLayout,
.vertex = wgpu::VertexState
{
.module = gpuShaderModule,
.entryPoint = "vert",
.bufferCount = 1,
.buffers = &vertexBufferLayout,
},
.primitive = wgpu::PrimitiveState
{
.topology = wgpu::PrimitiveTopology::TriangleList,
.stripIndexFormat = wgpu::IndexFormat::Undefined,
.frontFace = wgpu::FrontFace::CCW,
.cullMode = wgpu::CullMode::None,
},
.depthStencil = &depthStencilState,
.multisample = wgpu::MultisampleState{},
.fragment = &fragmentState,
};
wgpu::RenderPipeline gpuRenderPipeline = gpuDevice.CreateRenderPipeline( &renderPipelineDescriptor);メインループ
前回作成したメインループに追加します。
pass にコマンドを設定し GPUに送信します。
wgpu::RenderPassEncoder pass = gpuCommandEncoder.BeginRenderPass( &renderPassDescriptor);
angle += 0.01f;
queue.WriteBuffer( uniformBuffer, 0, &angle, sizeof( angle));
pass.SetPipeline( gpuRenderPipeline);
pass.SetBindGroup( 0, gpuBindGroup, 0, 0);
pass.SetVertexBuffer( 0, vertexBuffer, 0, WGPU_WHOLE_SIZE);
pass.SetIndexBuffer( indexBuffer, wgpu::IndexFormat::Uint16, 0, WGPU_WHOLE_SIZE);
pass.DrawIndexed( 3, 1, 0, 0, 0);
pass.End();
wgpu::CommandBuffer commands = gpuCommandEncoder.Finish();
queue.Submit( 1, &commands);- まず 回転を更新し uniformBuffer を書き込みます。
- RenderPipeline と BindGroup を設定します。
- 頂点バッファを設定します。
- インデックスバッファを設定します。
DrawIndexed で描画コマンドを送ります。
完成
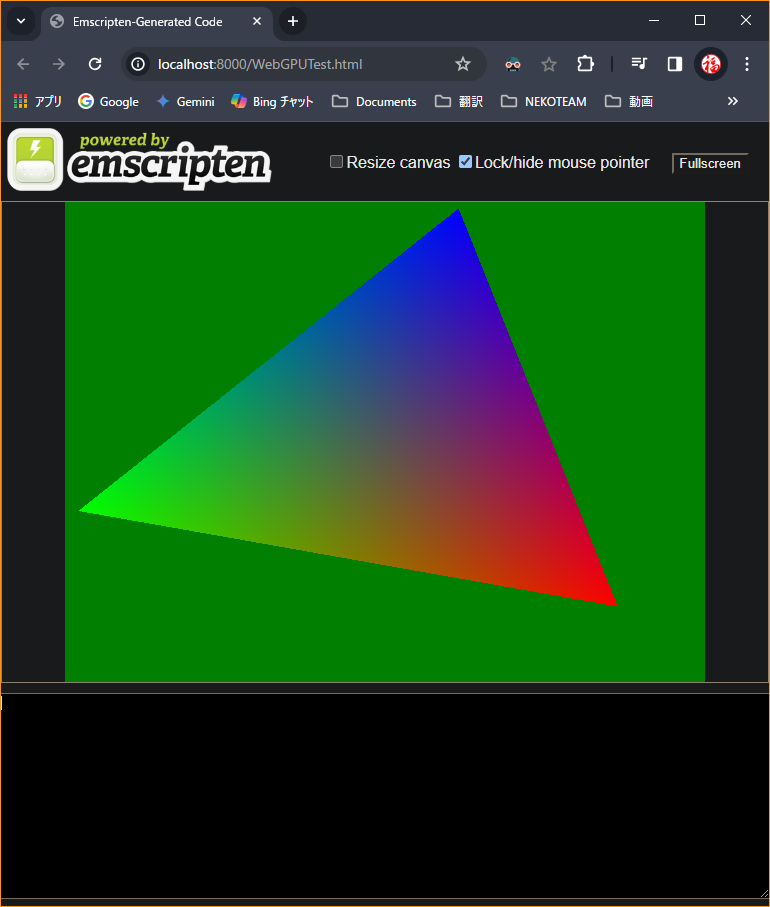
これで超単純なプリミティブを描画出来ました。
画面比率が 4:3 で三角形が歪んでますが、次回カメラ設定で解決します。
コード全体
#include <iostream>
#include <cmath>
#include <numbers>
#include <webgpu/webgpu_cpp.h>
#include <emscripten.h>
//----------------------------------------------------------------------------
int main()
{
wgpu::Instance gpuInstance = wgpu::CreateInstance();
// Adapter取得
wgpu::Adapter gpuAdapter{};
const wgpu::RequestAdapterOptions adapterOptions{};
gpuInstance.RequestAdapter(
&adapterOptions,
[]( WGPURequestAdapterStatus status, WGPUAdapter adapter, const char* message, void* userdata)
{
if( status != WGPURequestAdapterStatus_Success)
{
std::cerr << "Could not get WebGPU adapter: " << message << std::endl;
exit( 0);
}
wgpu::Adapter& gpuAdapter = *reinterpret_cast<wgpu::Adapter*>( userdata);
gpuAdapter = wgpu::Adapter::Acquire( adapter);
},
reinterpret_cast<void*>( &gpuAdapter)
);
while( !gpuAdapter) emscripten_sleep( 1000/60);
// Device取得
wgpu::Device gpuDevice{};
wgpu::DeviceDescriptor deviceDescriptor{};
gpuAdapter.RequestDevice(
&deviceDescriptor,
[]( WGPURequestDeviceStatus status, WGPUDevice device, const char* message, void* userdata)
{
if( status != WGPURequestDeviceStatus_Success)
{
std::cerr << "Could not get WebGPU device: " << message << std::endl;
exit( 0);
}
wgpu::Device& gpuDevice = *reinterpret_cast<wgpu::Device*>( userdata);
gpuDevice = wgpu::Device::Acquire( device);
},
reinterpret_cast<void*>( &gpuDevice)
);
while( !gpuDevice) emscripten_sleep( 1000/60);
// エラーキャッチ設定
gpuDevice.SetUncapturedErrorCallback(
[](WGPUErrorType type, char const * message, void * userdata)
{
std::cout << type << ": " << message << std::endl;
},
nullptr
);
// コマンドキューの取得
wgpu::Queue queue = gpuDevice.GetQueue();
// 描画サーフェス作成
wgpu::SurfaceDescriptorFromCanvasHTMLSelector surfaceDescriptorFromCanvasHTMLSelector{};
surfaceDescriptorFromCanvasHTMLSelector.selector = "#canvas";
wgpu::SurfaceDescriptor surfaceDescriptor
{
.nextInChain = &surfaceDescriptorFromCanvasHTMLSelector,
};
wgpu::Surface gpuSurface = gpuInstance.CreateSurface( &surfaceDescriptor);
// スワップチェーン作成
wgpu::TextureFormat gpuTextureFormat = gpuSurface.GetPreferredFormat( gpuAdapter);
wgpu::SwapChainDescriptor swapChainDescriptor
{
.usage = wgpu::TextureUsage::RenderAttachment,
.format = wgpu::TextureFormat::BGRA8Unorm,
.width = 640,
.height = 480,
.presentMode = wgpu::PresentMode::Fifo,
};
wgpu::SwapChain gpuSwapChain = gpuDevice.CreateSwapChain( gpuSurface, &swapChainDescriptor);
// 深度・ステンシルバッファ作成
wgpu::TextureDescriptor textureDescriptor
{
.usage = wgpu::TextureUsage::RenderAttachment,
.size = wgpu::Extent3D
{
.width = 640,
.height = 480,
.depthOrArrayLayers = 1,
},
.format = wgpu::TextureFormat::Depth24PlusStencil8,
};
wgpu::Texture gpuTextureDepthStenci = gpuDevice.CreateTexture( &textureDescriptor);
wgpu::TextureView textureViewDepthStenci = gpuTextureDepthStenci.CreateView();
// 深度・ステンシルステート作成
wgpu::DepthStencilState depthStencilState
{
.format = wgpu::TextureFormat::Depth24PlusStencil8,
.depthWriteEnabled = true,
.depthCompare = wgpu::CompareFunction::Less,
.stencilFront = wgpu::StencilFaceState{},
.stencilBack = wgpu::StencilFaceState{},
.stencilReadMask = 0xFFFFFFFF,
.stencilWriteMask = 0xFFFFFFFF,
.depthBias = 0,
.depthBiasSlopeScale = 0.0f,
.depthBiasClamp = 0.0f,
};
// シェーダーのコンパイル
char const wgsl_shader[] = R"(
struct VSIn {
@location(0) pos: vec2<f32>,
@location(1) color: vec3<f32>,
};
struct V2F {
@builtin(position) pos: vec4<f32>,
@location( 0) color: vec3<f32>,
};
struct Uniform
{
angle: f32,
};
@group(0) @binding(0) var<uniform> _Uniform : Uniform;
@vertex
fn vert( in: VSIn) -> V2F {
var out: V2F;
let cs = cos( _Uniform.angle);
let sn = sin( _Uniform.angle);
let mtx: mat2x2<f32> = mat2x2<f32>( cs, -sn, sn, cs);
let pos = in.pos * mtx;
out.pos = vec4<f32>( pos.x, pos.y, 0.0f, 1.0f);
out.color = in.color;
return out;
}
//
@fragment
fn frag( in: V2F) -> @location(0) vec4<f32> {
return vec4<f32>( in.color, 1.0f);
}
)";
wgpu::ShaderModuleWGSLDescriptor shaderModuleWGSLDescriptor{};
shaderModuleWGSLDescriptor.code = wgsl_shader;
wgpu::ShaderModuleDescriptor shaderModuleDescriptor
{
.nextInChain = &shaderModuleWGSLDescriptor,
};
wgpu::ShaderModule gpuShaderModule = gpuDevice.CreateShaderModule( &shaderModuleDescriptor);
const float pi = 2*std::asin(1);
// 頂点情報
float const vertices[] =
{
std::sinf( 2*pi*0/3.0f), std::cosf( 2*pi*0/3.0f), 0.0f, 0.0f, 1.0f,
std::sinf( 2*pi*1/3.0f), std::cosf( 2*pi*1/3.0f), 1.0f, 0.0f, 0.0f,
std::sinf( 2*pi*2/3.0f), std::cosf( 2*pi*2/3.0f), 0.0f, 1.0f, 0.0f,
};
wgpu::BufferDescriptor vertexBufferDescriptor
{
.label = "vertices",
.usage = wgpu::BufferUsage::CopyDst | wgpu::BufferUsage::Vertex,
.size = sizeof( vertices),
};
wgpu::Buffer vertexBuffer = gpuDevice.CreateBuffer( &vertexBufferDescriptor);
queue.WriteBuffer( vertexBuffer, 0, vertices, sizeof( vertices));
// 頂点情報レイアウト設定
wgpu::VertexAttribute vertexAttributeArray[] =
{
{
.format = wgpu::VertexFormat::Float32x2,
.offset = 0,
.shaderLocation = 0,
},
{
.format = wgpu::VertexFormat::Float32x3,
.offset = 2 * sizeof( float),
.shaderLocation = 1,
},
};
wgpu::VertexBufferLayout vertexBufferLayout
{
.arrayStride = 5 * sizeof(float),
.attributeCount = std::size( vertexAttributeArray),
.attributes = vertexAttributeArray,
};
// インデックス情報
uint16_t const indices[] = { 0, 1, 2, 0, };
wgpu::BufferDescriptor indexBufferDescriptor
{
.label = "indices",
.usage = wgpu::BufferUsage::CopyDst | wgpu::BufferUsage::Index,
.size = sizeof( indices),
};
wgpu::Buffer indexBuffer = gpuDevice.CreateBuffer( &indexBufferDescriptor);
queue.WriteBuffer( indexBuffer, 0, indices, sizeof( indices));
// ブレンド設定
wgpu::BlendState blendState
{
.color = wgpu::BlendComponent
{
.operation = wgpu::BlendOperation::Add,
.srcFactor = wgpu::BlendFactor::SrcAlpha,
.dstFactor = wgpu::BlendFactor::OneMinusSrcAlpha,
},
.alpha = wgpu::BlendComponent
{
.operation = wgpu::BlendOperation::Add,
.srcFactor = wgpu::BlendFactor::Zero,
.dstFactor = wgpu::BlendFactor::One,
},
};
wgpu::ColorTargetState colorTargetState
{
.format = gpuTextureFormat,
.blend = &blendState,
.writeMask = wgpu::ColorWriteMask::All,
};
// フラグメント設定
wgpu::FragmentState fragmentState
{
.module = gpuShaderModule,
.entryPoint = "frag",
.constantCount = 0,
.constants = nullptr,
.targetCount = 1,
.targets = &colorTargetState,
};
// uniformレイアウト設定
wgpu::BindGroupLayoutEntry bindGroupLayoutEntryArray[]
{
{
.binding = 0,
.visibility = wgpu::ShaderStage::Vertex | wgpu::ShaderStage::Fragment,
.buffer = wgpu::BufferBindingLayout
{
.type = wgpu::BufferBindingType::Uniform,
.hasDynamicOffset = false,
.minBindingSize = 0,
},
},
};
wgpu::BindGroupLayoutDescriptor bindGroupLayoutDescriptor
{
.entryCount = std::size( bindGroupLayoutEntryArray),
.entries = bindGroupLayoutEntryArray,
};
wgpu::BindGroupLayout gpuBindGroupLayout = gpuDevice.CreateBindGroupLayout( &bindGroupLayoutDescriptor);
// uniformバッファーの設定
wgpu::BufferDescriptor uniformBufferDescriptor
{
.label = "uniform",
.usage = wgpu::BufferUsage::CopyDst | wgpu::BufferUsage::Uniform,
.size = 4*sizeof( float),
};
wgpu::Buffer uniformBuffer = gpuDevice.CreateBuffer( &uniformBufferDescriptor);
// BindGroupEntry 設定
wgpu::BindGroupEntry bindGroupEntryArray[]
{
{
.binding = 0,
.buffer = uniformBuffer,
.offset = 0,
.size = 4*sizeof(float),
.sampler = nullptr,
.textureView = nullptr,
},
};
wgpu::BindGroupDescriptor bindGroupDescriptor
{
.layout = gpuBindGroupLayout,
.entryCount = std::size( bindGroupEntryArray),
.entries = bindGroupEntryArray,
};
wgpu::BindGroup gpuBindGroup = gpuDevice.CreateBindGroup( &bindGroupDescriptor);
// レンダリングパイプライン作成
wgpu::PipelineLayoutDescriptor pipelineLayoutDescriptor
{
.bindGroupLayoutCount = 1,
.bindGroupLayouts = &gpuBindGroupLayout,
};
wgpu::PipelineLayout gpuPipelineLayout = gpuDevice.CreatePipelineLayout( &pipelineLayoutDescriptor);
wgpu::RenderPipelineDescriptor renderPipelineDescriptor
{
.layout = gpuPipelineLayout,
.vertex = wgpu::VertexState
{
.module = gpuShaderModule,
.entryPoint = "vert",
.bufferCount = 1,
.buffers = &vertexBufferLayout,
},
.primitive = wgpu::PrimitiveState
{
.topology = wgpu::PrimitiveTopology::TriangleList,
.stripIndexFormat = wgpu::IndexFormat::Undefined,
.frontFace = wgpu::FrontFace::CCW,
.cullMode = wgpu::CullMode::None,
},
.depthStencil = &depthStencilState,
.multisample = wgpu::MultisampleState{},
.fragment = &fragmentState,
};
wgpu::RenderPipeline gpuRenderPipeline = gpuDevice.CreateRenderPipeline( &renderPipelineDescriptor);
float angle = 0.0f;
while(true)
{
static int count = 0;
wgpu::CommandEncoder gpuCommandEncoder = gpuDevice.CreateCommandEncoder();
wgpu::TextureView gpuTextureView = gpuSwapChain.GetCurrentTextureView();
if( !gpuTextureView)
{
std::cerr << "Cannot acquire next swap chain texture" << std::endl;
exit( 0);
}
wgpu::RenderPassColorAttachment renderPassColorAttachment
{
.view = gpuTextureView,
.resolveTarget = nullptr,
.loadOp = wgpu::LoadOp::Clear,
.storeOp = wgpu::StoreOp::Store,
.clearValue = {0, 0.5f, 0, 1},
};
wgpu::RenderPassDepthStencilAttachment renderPassDepthStencilAttachment
{
.view = textureViewDepthStenci,
.depthLoadOp = wgpu::LoadOp::Clear,
.depthStoreOp = wgpu::StoreOp::Store,
.depthClearValue = 1.0f,
.depthReadOnly = false,
.stencilLoadOp = wgpu::LoadOp::Clear,
.stencilStoreOp = wgpu::StoreOp::Store,
.stencilClearValue = 0,
.stencilReadOnly = false,
};
wgpu::RenderPassDescriptor renderPassDescriptor
{
.colorAttachmentCount = 1,
.colorAttachments = &renderPassColorAttachment,
.depthStencilAttachment = &renderPassDepthStencilAttachment,
};
wgpu::RenderPassEncoder pass = gpuCommandEncoder.BeginRenderPass( &renderPassDescriptor);
angle += 0.01f;
queue.WriteBuffer( uniformBuffer, 0, &angle, sizeof( angle));
pass.SetPipeline( gpuRenderPipeline);
pass.SetBindGroup( 0, gpuBindGroup, 0, 0);
pass.SetVertexBuffer( 0, vertexBuffer, 0, WGPU_WHOLE_SIZE);
pass.SetIndexBuffer( indexBuffer, wgpu::IndexFormat::Uint16, 0, WGPU_WHOLE_SIZE);
pass.DrawIndexed( 3, 1, 0, 0, 0);
pass.End();
wgpu::CommandBuffer commands = gpuCommandEncoder.Finish();
queue.Submit( 1, &commands);
emscripten_sleep( 1000/60);
};
return 0;
}次回
カメラ設定と、uniform の複数設定を目指します。